单边递归优化
在快排函数的实现过程中,当本层完成了 partition 操作以后,剩余的工作就是等待着左边和右边的排序完成。代码如下所示:
quick_sort(arr, l, x - 1); // 对左半边排序
quick_sort(arr, x + 1 , r); // 对右半边排序这段代码就分别对基准值的左右两边进行了排序的递归调用。从程序的运行时间来考虑的话,我们每次函数调用,都会消耗掉一部分运行时间。那只要我们可以减少函数调用的次数,其实就可以加快一点程序运行的速度。
因此,单边递归优化的方式,就是当本层完成了 partition 操作以后,让本层继续完成基准值左边的 partition 操作,而基准值右边的排序工作交给下一层递归函数去处理。
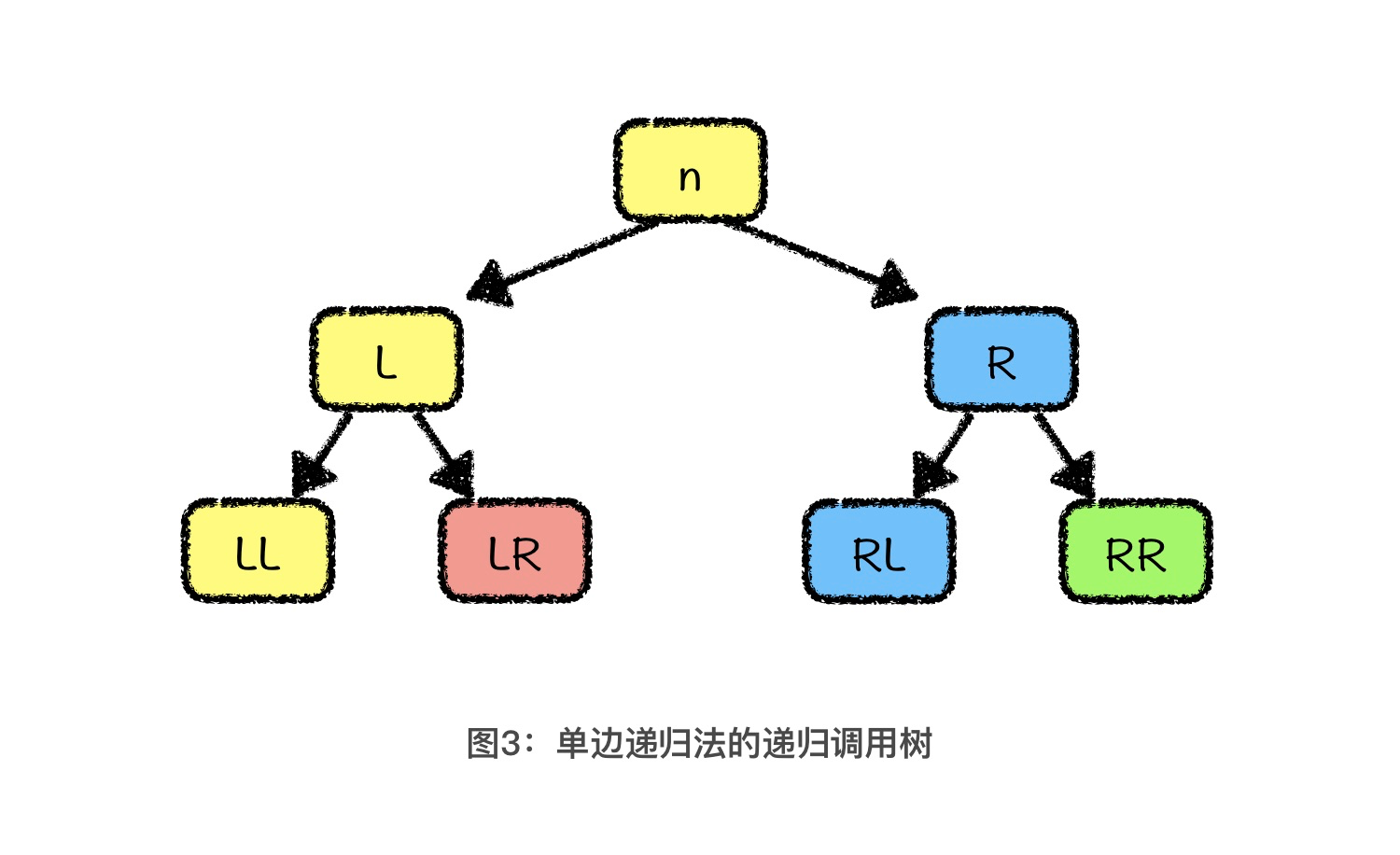
经过单边递归优化后生成的递归树如上图所示,为了方便你理解,我把在同一个函数调用内的操作用同样的颜色表示。一共用了黄色、红色、蓝色、绿色这 4 种颜色,也就是说我们实际调用了 4 次函数。而如果不采用单边递归法,实际发生的函数调用次数就是图中二叉树的节点个数,也就是 7 次。可见,我们采用了单边递归法以后,函数实际调用次数减少了一半。
下面是一段单边递归法的代码:
void quick_sort(int *arr, int l, int r) {
while (l < r) {
// 进行一轮 partition 操作
// 获得基准值的位置
int ind = partition(arr, l, r);
// 右侧正常调用递归函数
quick_sort(arr, ind + 1, r);
// 用本层处理左侧的排序
r = ind - 1;
}
return ;
}从代码中可知,l 和 r 是数组中待排序的区间范围,ind 是本轮 partition 操作后基准值的位置。当找到基准值的位置以后,对于右侧从 ind + 1 到 r 位置,我们就正常调用递归函数。然后,我们通过将 r 设置为 ind - 1,直接利用本层 while 循环逻辑,继续对左侧进行 partition 等相关排序操作。
基准值选取优化
如果基准值选取不合理的话,快速排序的时间复杂度有可能达到 O(n2) 这个量级,也就是退化成和选择排序、插入排序等算法一样的时间复杂度。只有当基准值每次都能将排序区间中的数据平分时,时间复杂度才是最好情况下的 O(nlogn)。
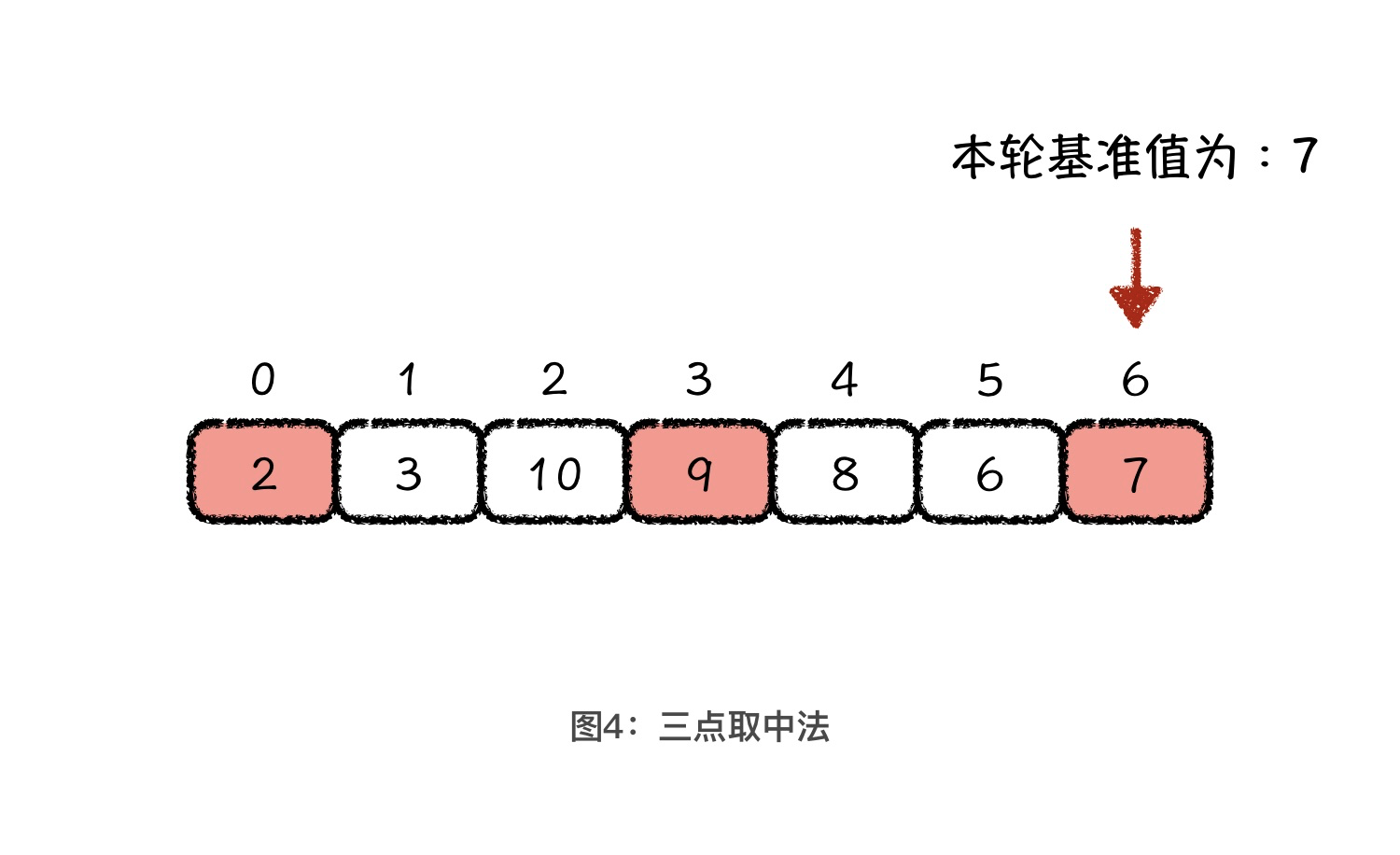
所谓三点取中法,就是每一轮取排序区间的头、尾和中间元素这三个值,然后把它们排序以后的中间值作为本轮的基准值。当然,你也可以根据自己的理解,调整要选取的这三个值的位置。我们就以上图为例,假设本轮的三个值分别为 2、9、7,中间值是 7,所以,本轮的基准值就是 7。
总结
- 单边递归法可以使快排过程中的递归调用次数减少一半,并且,这种优化方法也可以使用在所有和快速排序类似的程序结构中;
- 三点取中法能帮助我们选出更加合理的基准值,保证快速排序的运行效率。



