核心思想
快速排序算法思想很简单,核心就是一句话:找到基准值的位置。
可以分成三步:
- 第一步,选择一个值作为基准值;
- 第二步,找到基准值的位置,并将小于基准值的元素放在基准值的前面,大于基准值的元素放在基准值的后面;
- 第三步,对基准值的左右两侧递归地进行这个过程。
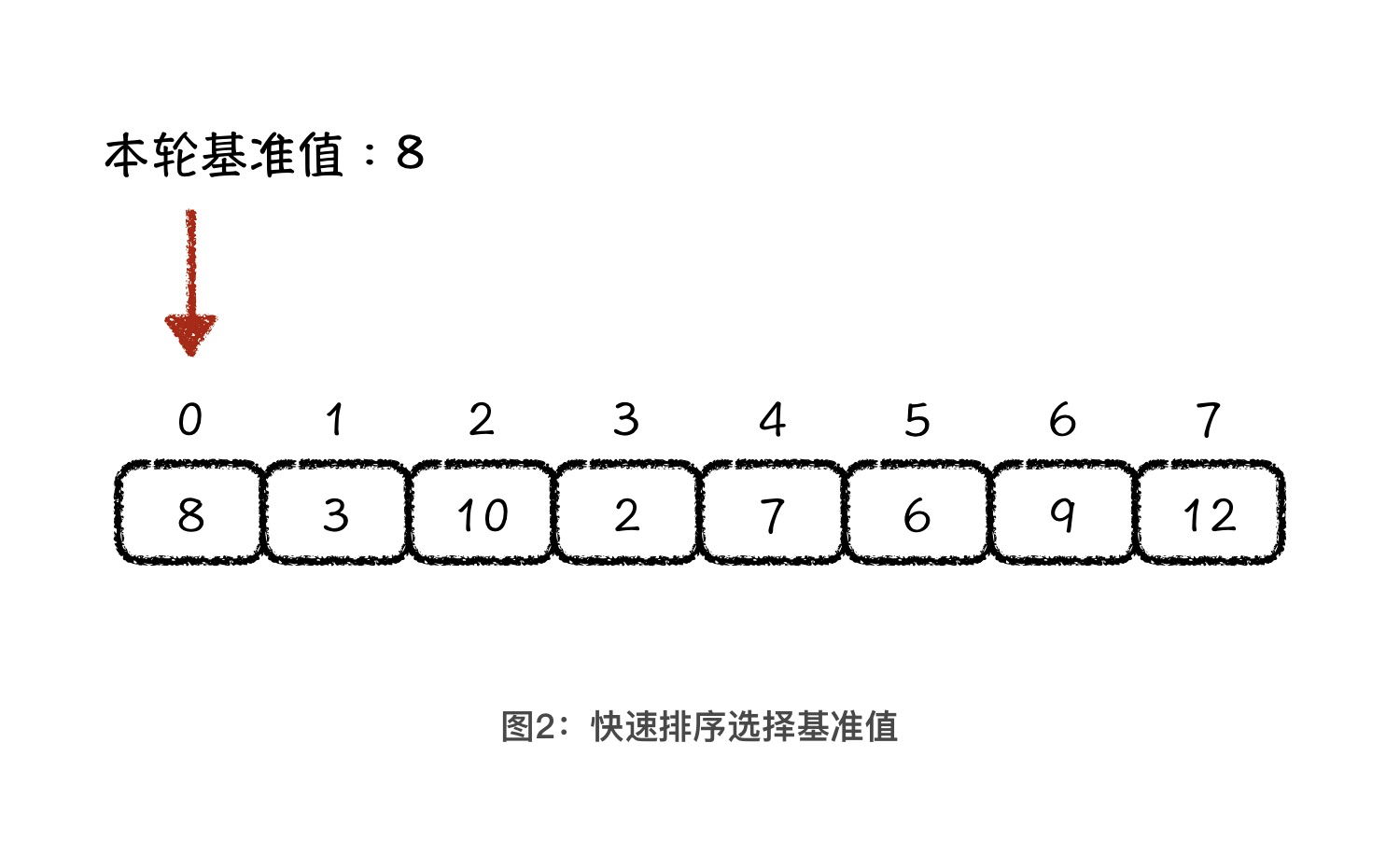
1:选择一个值作为基准值
最简单的选择方法,一定是选择待排序区间的头部元素作为基准值。
2:将小于基准值的元素放在基准值的前面,将大于基准值的元素放在基准值的后面
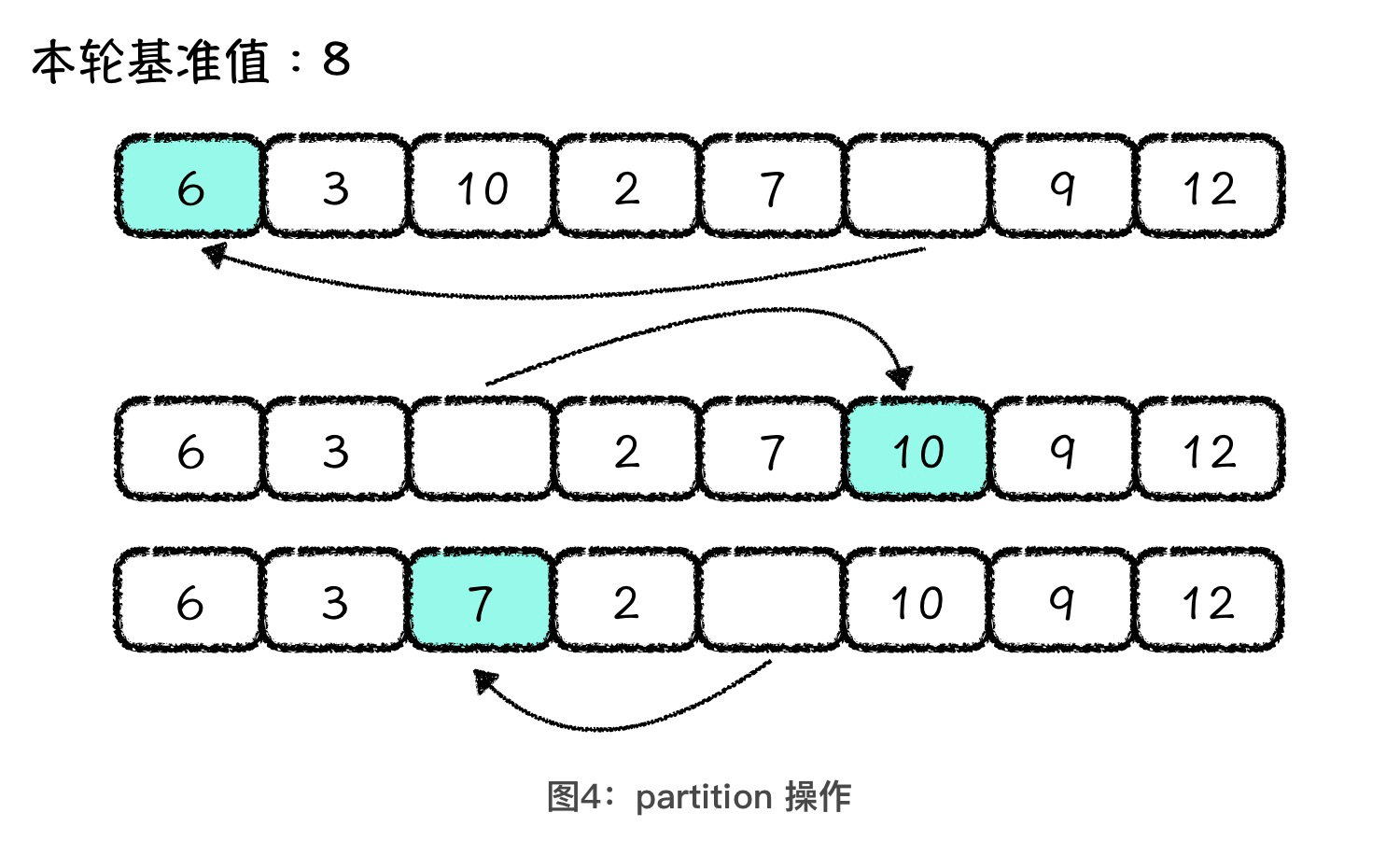
这一步通常被叫做 partition 操作,中文直译过来就是分割操作,也就是用基准值将原数组分割成前后两部分。
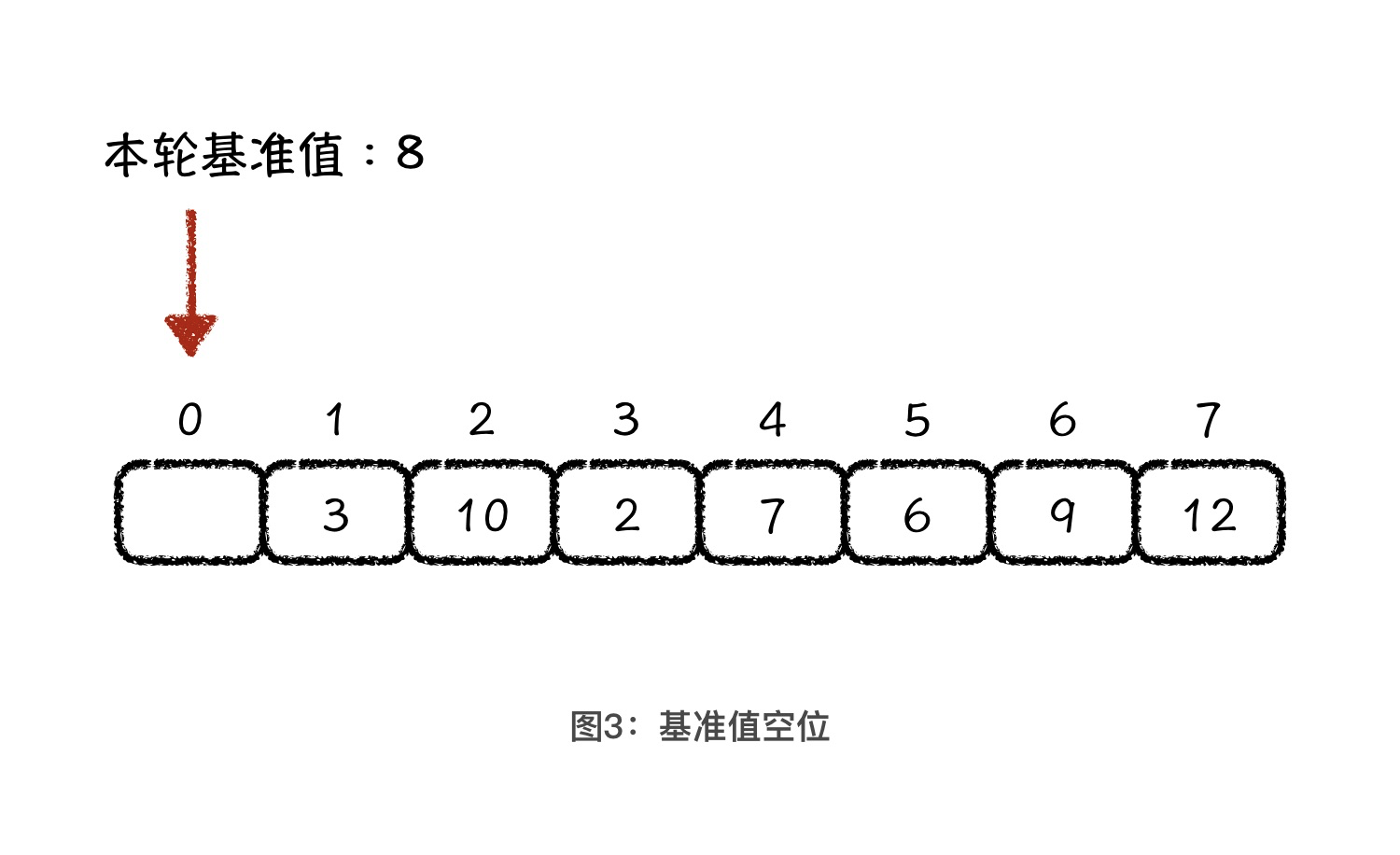
partition 操作简单来说,就是空出一个位置,反复地前后调换元素。
当我们选择了基准值以后,原先基准值的位置就相当于被空出来了,也就是说数组的第一位是空着的。
将后面小于基准值的元素放到前面的空位上,这样后面就空出一位了。然后,我们再将前面大于基准值的元素放到后面这个空位上。就这样交替进行,直到空位前面的值都小于基准值,空位后面的值都大于基准值为止。
3:对基准值的左右两侧,递归地进行第一步和第二步
要分别对 6、3、7、2 和 10、9、12 这两部分,再做选择基准值、找基准值位置和递归这三步。由于每次 partition 操作中,都会确定一个值,也就是基准值的正确位置,所以,经过有限次递归操作以后,整个数组也就变成了一个有序数组。
分析快速排序的时间复杂度
在讲快速排序算法过程的时候,我们说其中最关键的步骤是理解 parition 操作。因此,分析快速排序的时间复杂度,我们也要先来分析 partition 操作这一步的时间复杂度。
在 partition 操作的过程中,头指针会循环扫描到基准值最后放置的位置,尾指针也会扫描到最后基准值放置的位置。这样,头尾指针扫描加在一起,其实相当于扫描了整个待排序数组的区域。因此,我们就能得出单次 partition 操作的时间复杂度为 O(n)。也就是说,当前数组区间中有 10 个元素时,我们大概操作 10 次就能找到基准值的位置了。清楚了单次操作的时间复杂度以后,我们就能知道总体的时间复杂度了。
首先,我们要确定总体时间复杂度的公式。我们用 T(n)表示对 n个元素的数组进行快速排序所用的时间,那么 T(n) 中应该包括了单次的 partition 操作用时,以及 parition 操作以后,我们对左右两个子数组分别做快速排序所用的时间,也就是 T(n) = n + T(L) + T(R)。其中 n是单次 partition 操作的用时,T(L)和 T(R)分别是对左右区间进行快速排序的用时,L 和 R分别代表左区间和右区间中元素的数量。
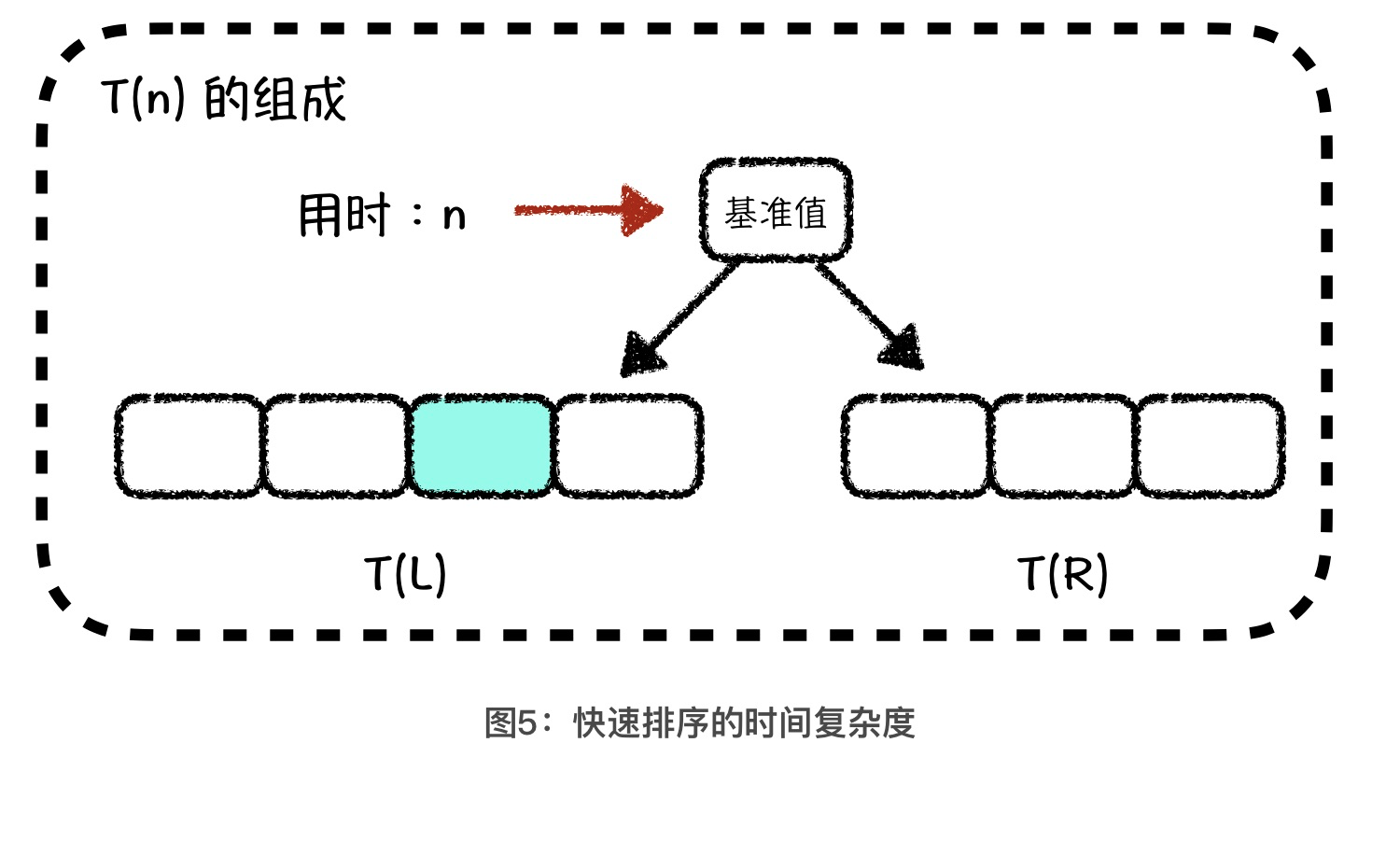
接着,我们借助二叉树的结构来求一下 T(n) 。首先,我们可以将基准值看成是由 n 个元素组成的二叉树的根节点,那么 partition 操作就是找到这个根节点的正确位置,总用时就是 n。如果我们将这个用时 n 当做二叉树根节点的独立用时,那么左子树根节点的独立用时就是 L,右子树根节点的独立用时就是 R。这样,我们就得到了这个二叉树第二层上所有节点的独立用时:L + R = n - 1。我们可以将这个值大致看成是 n。依照此方法,你会得到接下来各层二叉树节点的独立用时,关系如图所示:
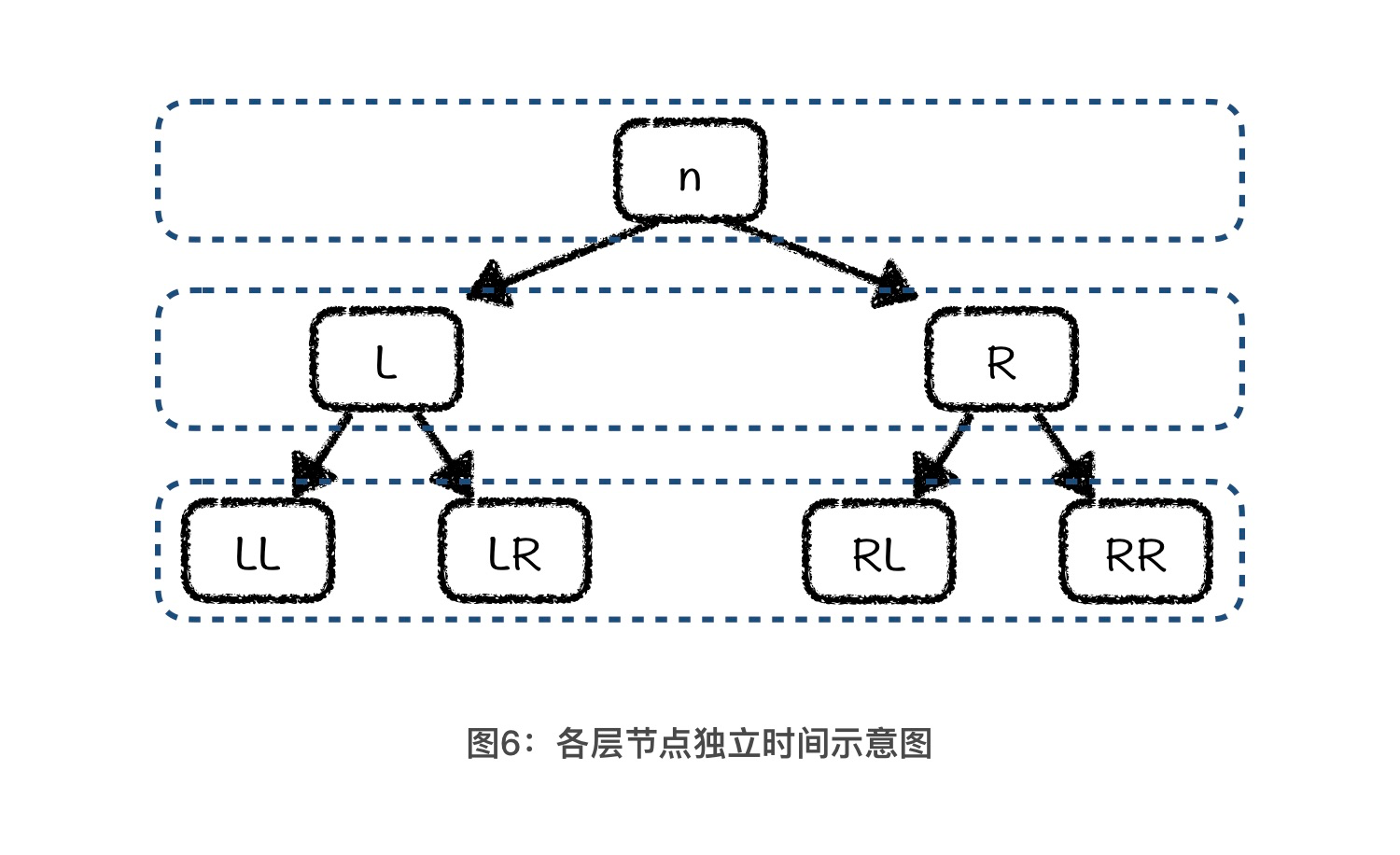
其中,每个节点上的数值代表了这个节点的独立用时。 n = L + R + 1,L = LL + LR + 1, R = RL + RR + 1。这也就意味着,第一层上节点的独立用时总和是 n,第二层上节点的独立用时总和是 L + R = n - 1,第三层上节点的独立用时总和是 LL + LR + RL + RR = n - 3。
其实,如果 n 足够大,那每一层上的所有节点的独立用时总和,我们都可以让其约等于 n。那快速排序的总用时,就可以约等于 n 乘上树的层数,也就是树的高度。因此,这棵树的高度越低,快速排序的效率越好,而树的高度越高,快速排序的效率也就越差。这样一来,我们就让树高这个直观的量和快速排序的效率有了概念上的关联。因此,我们只需要分析树高,就能分析清楚快速排序的执行效率了。
那针对有 n 个节点的二叉树(每个节点代表一个基准值,n 个节点就代表确定了 n 个基准值的位置),我们该怎么确定树高的范围呢?稍微一分析,你会发现,树高最低是 log2(n+1) ,也就是每个节点的左右两棵子树,所包含节点数量都差不多。这就意味着,我们每次选择基准值的时候,都要尽可能选择处在待排序数组中间的数字。也只有这样,快速排序算法才会达到最好的时间复杂度,也就是 O(nlog2n)。
结合二叉树的结构,我们分析了快速排序的最好时间复杂度。而快速排序的最坏时间复杂度是 O(n^2)
总结
- 先选择一个基准值,一般选择第一个元素,基准值位置空缺;
- 基准值和最后的元素开始比较,如果小于基准值,则移动到空缺的位置;
- 基准值和最前的元素开始比较,如果大于基准值,则移动到空缺的位置;
- 不断执行第二和第三步骤,确定基准值的位置;
- 对基准值两边的元素集合递归执行1234步骤。



