本文章仅用于本人学习笔记记录
微信:A20991212A(如本文档内容侵权了您的权益,请您通过微信联系到我)
组合模式介绍

从上图可以看到这有点像螺丝🔩和螺母,通过一堆的链接组织出一棵结构树。而这种通过把相似对象(也可以称作是方法)组合成一组可被调用的结构树对象的设计思路叫做组合模式。组合模式也就是把相似对象(也可以称作是方法)组合成一组可被调用的结构树对象。
这种设计方式可以让你的服务组节点进行自由组合对外提供服务,例如你有三个原子校验功能(A:身份证、B:银行卡、C:手机号)服务并对外提供调用使用。有些调用方需要使用AB组合,有些调用方需要使用到CBA组合,还有一些可能只使用三者中的一个。那么这个时候你就可以使用组合模式进行构建服务,对于不同类型的调用方配置不同的组织关系树,而这个树结构你可以配置到数据库中也可以不断的通过图形界面来控制树结构。
所以不同的设计模式用在恰当好处的场景可以让代码逻辑非常清晰并易于扩展,同时也可以减少团队新增人员对项目的学习成本。
简单例子
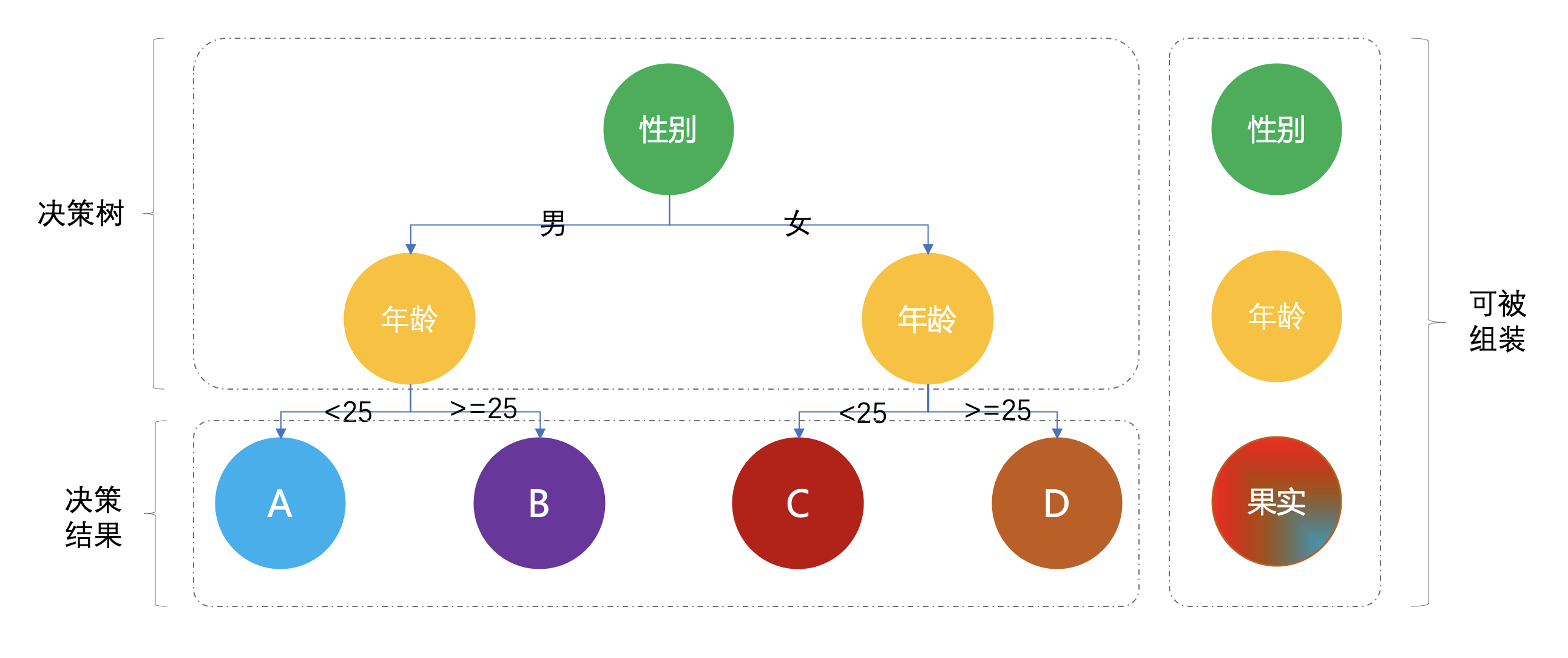
以上是一个非常简化版的营销规则决策树,根据性别、年龄来发放不同类型的优惠券,来刺激消费起到精准用户促活的目的。
用一坨坨代码实现
工程结构
itstack-demo-design-8-01
└── src
└── main
└── java
└── org.itstack.demo.design
└── EngineController.java
代码实现
public class EngineController {
private Logger logger = LoggerFactory.getLogger(EngineController.class);
public String process(final String userId, final String userSex, final int userAge) {
logger.info("ifelse实现方式判断用户结果。userId:{} userSex:{} userAge:{}", userId, userSex, userAge);
if ("man".equals(userSex)) {
if (userAge < 25) {
return "果实A";
}
if (userAge >= 25) {
return "果实B";
}
}
if ("woman".equals(userSex)) {
if (userAge < 25) {
return "果实C";
}
if (userAge >= 25) {
return "果实D";
}
}
return null;
}
}
组合模式重构代码
接下来的重构部分代码改动量相对来说会比较大一些,为了让我们可以把不同类型的决策节点和最终的果实组装成一棵可被运行的决策树,需要做适配设计和工厂方法调用,具体会体现在定义接口以及抽象类和初始化配置决策节点(性别、年龄)上。建议这部分代码多阅读几次,最好实践下。
工程结构
itstack-demo-design-8-02
└── src
├── main
│ └── java
│ └── org.itstack.demo.design.domain
│ ├── model
│ │ ├── aggregates
│ │ │ └── TreeRich.java
│ │ └── vo
│ │ ├── EngineResult.java
│ │ ├── TreeNode.java
│ │ ├── TreeNodeLink.java
│ │ └── TreeRoot.java
│ └── service
│ ├── engine
│ │ ├── impl
│ │ │ └── TreeEngineHandle.java
│ │ ├── EngineBase.java
│ │ ├── EngineConfig.java
│ │ └── IEngine.java
│ └── logic
│ ├── impl
│ │ ├── LogicFilter.java
│ │ └── LogicFilter.java
│ └── LogicFilter.java
└── test
└── java
└── org.itstack.demo.design.test
└── ApiTest.java
组合模式模型结构
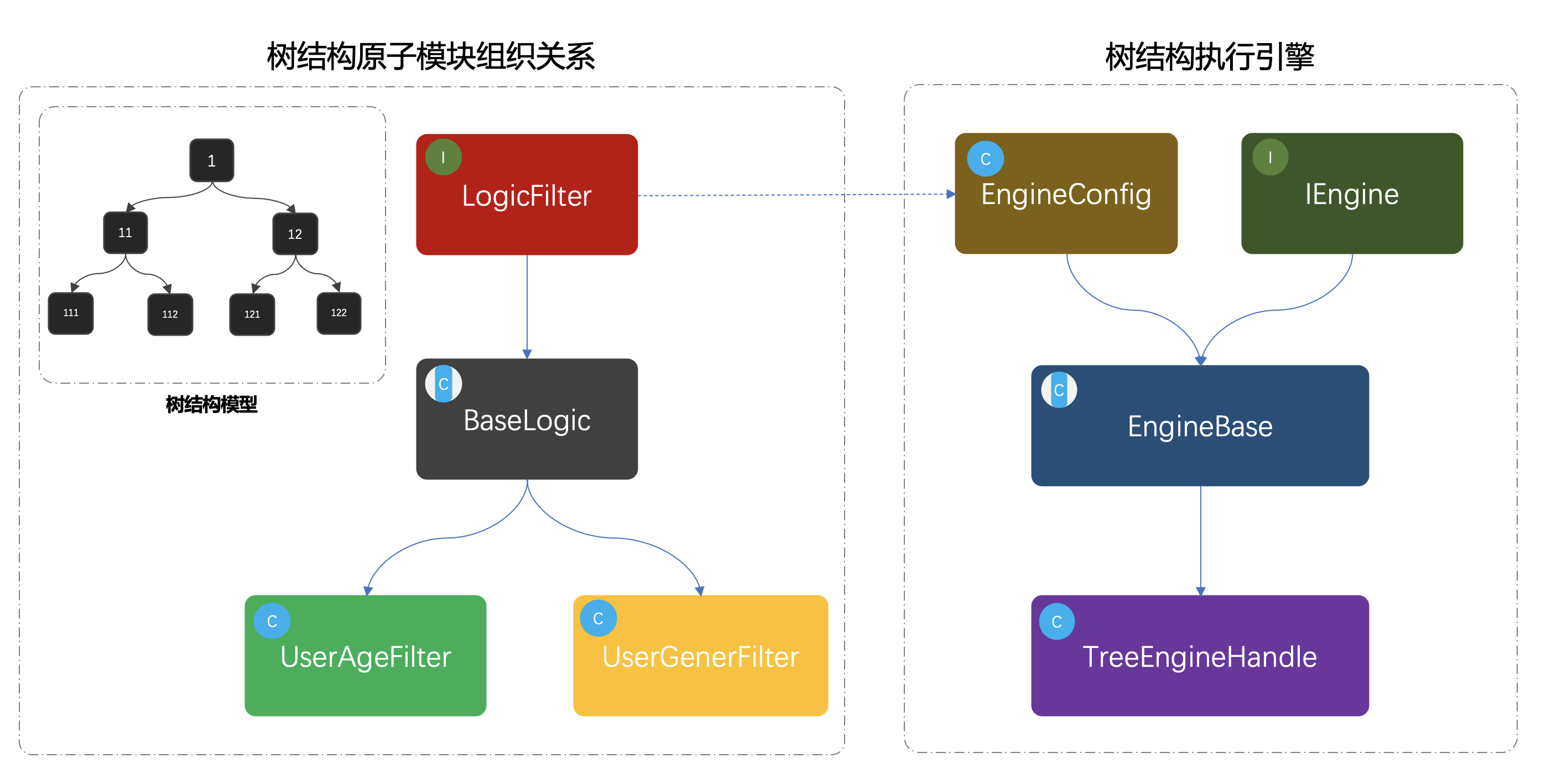
LogicFilter开始定义适配的决策过滤器,BaseLogic是对接口的实现,提供最基本的通用方法。UserAgeFilter、UserGenerFilter,是两个具体的实现类用于判断年龄和性别。
代码实现
基础对象

以上这部分简单介绍,不包含逻辑只是各项必要属性的get/set
树节点逻辑过滤器接口
public interface LogicFilter {
/**
* 逻辑决策器
*
* @param matterValue 决策值
* @param treeNodeLineInfoList 决策节点
* @return 下一个节点Id
*/
Long filter(String matterValue, List<TreeNodeLink> treeNodeLineInfoList);
/**
* 获取决策值
*
* @param decisionMatter 决策物料
* @return 决策值
*/
String matterValue(Long treeId, String userId, Map<String, String> decisionMatter);
}
这一部分定义了适配的通用接口,逻辑决策器、获取决策值,让每一个提供决策能力的节点都必须实现此接口,保证统一性。
决策抽象类提供基础服务
public abstract class BaseLogic implements LogicFilter {
@Override
public Long filter(String matterValue, List<TreeNodeLink> treeNodeLinkList) {
for (TreeNodeLink nodeLine : treeNodeLinkList) {
if (decisionLogic(matterValue, nodeLine)) return nodeLine.getNodeIdTo();
}
return 0L;
}
@Override
public abstract String matterValue(Long treeId, String userId, Map<String, String> decisionMatter);
private boolean decisionLogic(String matterValue, TreeNodeLink nodeLink) {
switch (nodeLink.getRuleLimitType()) {
case 1:
return matterValue.equals(nodeLink.getRuleLimitValue());
case 2:
return Double.parseDouble(matterValue) > Double.parseDouble(nodeLink.getRuleLimitValue());
case 3:
return Double.parseDouble(matterValue) < Double.parseDouble(nodeLink.getRuleLimitValue());
case 4:
return Double.parseDouble(matterValue) <= Double.parseDouble(nodeLink.getRuleLimitValue());
case 5:
return Double.parseDouble(matterValue) >= Double.parseDouble(nodeLink.getRuleLimitValue());
default:
return false;
}
}
}
在抽象方法中实现了接口方法,同时定义了基本的决策方法;1、2、3、4、5,等于、小于、大于、小于等于、大于等于的判断逻辑。
同时定义了抽象方法,让每一个实现接口的类都必须按照规则提供决策值,这个决策值用于做逻辑比对。
树节点逻辑实现类
年龄节点
public class UserAgeFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("age");
}
}
性别节点
public class UserGenderFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("gender");
}
}
以上两个决策逻辑的节点获取值的方式都非常简单,只是获取用户的入参即可。实际的业务开发可以从数据库、RPC接口、缓存运算等各种方式获取。
决策引擎接口定义
public interface IEngine {
EngineResult process(final Long treeId, final String userId, TreeRich treeRich, final Map<String, String> decisionMatter);
}
对于使用方来说也同样需要定义统一的接口操作,这样的好处非常方便后续拓展出不同类型的决策引擎,也就是可以建造不同的决策工厂。
决策节点配置
public class EngineConfig {
static Map<String, LogicFilter> logicFilterMap;
static {
logicFilterMap = new ConcurrentHashMap<>();
logicFilterMap.put("userAge", new UserAgeFilter());
logicFilterMap.put("userGender", new UserGenderFilter());
}
public Map<String, LogicFilter> getLogicFilterMap() {
return logicFilterMap;
}
public void setLogicFilterMap(Map<String, LogicFilter> logicFilterMap) {
this.logicFilterMap = logicFilterMap;
}
}
在这里将可提供服务的决策节点配置到map结构中,对于这样的map结构可以抽取到数据库中,那么就可以非常方便的管理。
基础决策引擎功能
public abstract class EngineBase extends EngineConfig implements IEngine {
private Logger logger = LoggerFactory.getLogger(EngineBase.class);
@Override
public abstract EngineResult process(Long treeId, String userId, TreeRich treeRich, Map<String, String> decisionMatter);
protected TreeNode engineDecisionMaker(TreeRich treeRich, Long treeId, String userId, Map<String, String> decisionMatter) {
TreeRoot treeRoot = treeRich.getTreeRoot();
Map<Long, TreeNode> treeNodeMap = treeRich.getTreeNodeMap();
// 规则树根ID
Long rootNodeId = treeRoot.getTreeRootNodeId();
TreeNode treeNodeInfo = treeNodeMap.get(rootNodeId);
//节点类型[NodeType];1子叶、2果实
while (treeNodeInfo.getNodeType().equals(1)) {
String ruleKey = treeNodeInfo.getRuleKey();
LogicFilter logicFilter = logicFilterMap.get(ruleKey);
String matterValue = logicFilter.matterValue(treeId, userId, decisionMatter);
Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLinkList());
treeNodeInfo = treeNodeMap.get(nextNode);
logger.info("决策树引擎=>{} userId:{} treeId:{} treeNode:{} ruleKey:{} matterValue:{}", treeRoot.getTreeName(), userId, treeId, treeNodeInfo.getTreeNodeId(), ruleKey, matterValue);
}
return treeNodeInfo;
}
}
这里主要提供决策树流程的处理过程,有点像通过链路的关系(性别、年龄)在二叉树中寻找果实节点的过程。
同时提供一个抽象方法,执行决策流程的方法供外部去做具体的实现。
决策引擎的实现
public class TreeEngineHandle extends EngineBase {
@Override
public EngineResult process(Long treeId, String userId, TreeRich treeRich, Map<String, String> decisionMatter) {
// 决策流程
TreeNode treeNode = engineDecisionMaker(treeRich, treeId, userId, decisionMatter);
// 决策结果
return new EngineResult(userId, treeId, treeNode.getTreeNodeId(), treeNode.getNodeValue());
}
}
这里对于决策引擎的实现就非常简单了,通过传递进来的必要信息;决策树信息、决策物料值,来做具体的树形结构决策。测试验证
组装树关系
@Before
public void init() {
// 节点:1
TreeNode treeNode_01 = new TreeNode();
treeNode_01.setTreeId(10001L);
treeNode_01.setTreeNodeId(1L);
treeNode_01.setNodeType(1);
treeNode_01.setNodeValue(null);
treeNode_01.setRuleKey("userGender");
treeNode_01.setRuleDesc("用户性别[男/女]");
// 链接:1->11
TreeNodeLink treeNodeLink_11 = new TreeNodeLink();
treeNodeLink_11.setNodeIdFrom(1L);
treeNodeLink_11.setNodeIdTo(11L);
treeNodeLink_11.setRuleLimitType(1);
treeNodeLink_11.setRuleLimitValue("man");
// 链接:1->12
TreeNodeLink treeNodeLink_12 = new TreeNodeLink();
treeNodeLink_12.setNodeIdTo(1L);
treeNodeLink_12.setNodeIdTo(12L);
treeNodeLink_12.setRuleLimitType(1);
treeNodeLink_12.setRuleLimitValue("woman");
List<TreeNodeLink> treeNodeLinkList_1 = new ArrayList<>();
treeNodeLinkList_1.add(treeNodeLink_11);
treeNodeLinkList_1.add(treeNodeLink_12);
treeNode_01.setTreeNodeLinkList(treeNodeLinkList_1);
// 节点:11
TreeNode treeNode_11 = new TreeNode();
treeNode_11.setTreeId(10001L);
treeNode_11.setTreeNodeId(11L);
treeNode_11.setNodeType(1);
treeNode_11.setNodeValue(null);
treeNode_11.setRuleKey("userAge");
treeNode_11.setRuleDesc("用户年龄");
// 链接:11->111
TreeNodeLink treeNodeLink_111 = new TreeNodeLink();
treeNodeLink_111.setNodeIdFrom(11L);
treeNodeLink_111.setNodeIdTo(111L);
treeNodeLink_111.setRuleLimitType(3);
treeNodeLink_111.setRuleLimitValue("25");
// 链接:11->112
TreeNodeLink treeNodeLink_112 = new TreeNodeLink();
treeNodeLink_112.setNodeIdFrom(11L);
treeNodeLink_112.setNodeIdTo(112L);
treeNodeLink_112.setRuleLimitType(5);
treeNodeLink_112.setRuleLimitValue("25");
List<TreeNodeLink> treeNodeLinkList_11 = new ArrayList<>();
treeNodeLinkList_11.add(treeNodeLink_111);
treeNodeLinkList_11.add(treeNodeLink_112);
treeNode_11.setTreeNodeLinkList(treeNodeLinkList_11);
// 节点:12
TreeNode treeNode_12 = new TreeNode();
treeNode_12.setTreeId(10001L);
treeNode_12.setTreeNodeId(12L);
treeNode_12.setNodeType(1);
treeNode_12.setNodeValue(null);
treeNode_12.setRuleKey("userAge");
treeNode_12.setRuleDesc("用户年龄");
// 链接:12->121
TreeNodeLink treeNodeLink_121 = new TreeNodeLink();
treeNodeLink_121.setNodeIdFrom(12L);
treeNodeLink_121.setNodeIdTo(121L);
treeNodeLink_121.setRuleLimitType(3);
treeNodeLink_121.setRuleLimitValue("25");
// 链接:12->122
TreeNodeLink treeNodeLink_122 = new TreeNodeLink();
treeNodeLink_122.setNodeIdFrom(12L);
treeNodeLink_122.setNodeIdTo(122L);
treeNodeLink_122.setRuleLimitType(5);
treeNodeLink_122.setRuleLimitValue("25");
List<TreeNodeLink> treeNodeLinkList_12 = new ArrayList<>();
treeNodeLinkList_12.add(treeNodeLink_121);
treeNodeLinkList_12.add(treeNodeLink_122);
treeNode_12.setTreeNodeLinkList(treeNodeLinkList_12);
// 节点:111
TreeNode treeNode_111 = new TreeNode();
treeNode_111.setTreeId(10001L);
treeNode_111.setTreeNodeId(111L);
treeNode_111.setNodeType(2);
treeNode_111.setNodeValue("果实A");
// 节点:112
TreeNode treeNode_112 = new TreeNode();
treeNode_112.setTreeId(10001L);
treeNode_112.setTreeNodeId(112L);
treeNode_112.setNodeType(2);
treeNode_112.setNodeValue("果实B");
// 节点:121
TreeNode treeNode_121 = new TreeNode();
treeNode_121.setTreeId(10001L);
treeNode_121.setTreeNodeId(121L);
treeNode_121.setNodeType(2);
treeNode_121.setNodeValue("果实C");
// 节点:122
TreeNode treeNode_122 = new TreeNode();
treeNode_122.setTreeId(10001L);
treeNode_122.setTreeNodeId(122L);
treeNode_122.setNodeType(2);
treeNode_122.setNodeValue("果实D");
// 树根
TreeRoot treeRoot = new TreeRoot();
treeRoot.setTreeId(10001L);
treeRoot.setTreeRootNodeId(1L);
treeRoot.setTreeName("规则决策树");
Map<Long, TreeNode> treeNodeMap = new HashMap<>();
treeNodeMap.put(1L, treeNode_01);
treeNodeMap.put(11L, treeNode_11);
treeNodeMap.put(12L, treeNode_12);
treeNodeMap.put(111L, treeNode_111);
treeNodeMap.put(112L, treeNode_112);
treeNodeMap.put(121L, treeNode_121);
treeNodeMap.put(122L, treeNode_122);
treeRich = new TreeRich(treeRoot, treeNodeMap);
}

- 重要,这一部分是组合模式非常重要的使用,在我们已经建造好的决策树关系下,可以创建出树的各个节点,以及对节点间使用链路进行串联。
- 及时后续你需要做任何业务的扩展都可以在里面添加相应的节点,并做动态化的配置。
- 关于这部分手动组合的方式可以提取到数据库中,那么也就可以扩展到图形界面的进行配置操作。
编写测试类
@Test
public void test_tree() {
logger.info("决策树组合结构信息:\r\n" + JSON.toJSONString(treeRich));
IEngine treeEngineHandle = new TreeEngineHandle();
Map<String, String> decisionMatter = new HashMap<>();
decisionMatter.put("gender", "man");
decisionMatter.put("age", "29");
EngineResult result = treeEngineHandle.process(10001L, "Oli09pLkdjh", treeRich, decisionMatter);
logger.info("测试结果:{}", JSON.toJSONString(result));
}
在这里提供了调用的通过组织模式创建出来的流程决策树,调用的时候传入了决策树的ID,那么如果是业务开发中就可以方便的解耦决策树与业务的绑定关系,按需传入决策树ID即可。
此外入参我们还提供了需要处理;男(man)、年龄(29岁),的参数信息。
测试结果
23:35:05.711 [main] INFO o.i.d.d.d.service.engine.EngineBase - 决策树引擎=>规则决策树 userId:Oli09pLkdjh treeId:10001 treeNode:11 ruleKey:userGender matterValue:man
23:35:05.712 [main] INFO o.i.d.d.d.service.engine.EngineBase - 决策树引擎=>规则决策树 userId:Oli09pLkdjh treeId:10001 treeNode:112 ruleKey:userAge matterValue:29
23:35:05.715 [main] INFO org.itstack.demo.design.test.ApiTest - 测试结果:{"nodeId":112,"nodeValue":"果实B","success":true,"treeId":10001,"userId":"Oli09pLkdjh"}
Process finished with exit code 0
从测试结果上看这与我们使用ifelse是一样的,但是目前这与的组合模式设计下,就非常方便后续的拓展和修改。
总结
从以上的决策树场景来看,组合模式的主要解决的是一系列简单逻辑节点或者扩展的复杂逻辑节点在不同结构的组织下,对于外部的调用是仍然可以非常简单的。
这部分设计模式保证了开闭原则,无需更改模型结构你就可以提供新的逻辑节点的使用并配合组织出新的关系树。但如果是一些功能差异化非常大的接口进行包装就会变得比较困难,但也不是不能很好的处理,只不过需要做一些适配和特定化的开发。
组合模式也就是把相似对象(也可以称作是方法)组合成一组可被调用的结构树对象。